 Making reliable distributed systems in the presence of software errors Making reliable distributed systems in the presence of software errors
started 11/12/2003; 2:35:58 PM - last post 11/19/2003; 6:02:09 AM
|
|
Luke Gorrie - Making reliable distributed systems in the presence of software errors 
11/12/2003; 2:35:58 PM (reads: 13174, responses: 26)
|
|
| Making reliable distributed systems in the presence of software errors |
|
The work described in this thesis is the result of a research program started in 1981 to find better ways of programming Telecom applications. These applications are large programs which despite careful testing will probably contain many errors when the program is put into service. We assume that such programs do contain errors, and investigate methods for building reliable systems despite such errors.
Joe Armstrong's much-awaited PhD thesis about the development of Erlang!
Posted to general by Luke Gorrie on 11/12/03; 2:49:41 PM
|
|

|
|
Manuel Simoni - Re: Making reliable distributed systems in the presence of s
11/12/2003; 5:23:06 PM (reads: 1103, responses: 1)
|
|
|
Thanks Luke, for the great pointer.
I have a question: Isn't the concept of unforgeable names security by obscurity?
|
|
andrew cooke - Re: Making reliable distributed systems in the presence of s
11/12/2003; 5:40:26 PM (reads: 1109, responses: 0)
|
|
|
I have a question: Isn't the concept of unforgeable names security by obscurity?
if this was a joke, sorry for the serious reply...!
security by obscurity means that the system is secure because someone does not know the implementation details (the algorithms).
all (i think?) security systems rely on some secret data: the state of random number generators, or private keys, for example. the reliance on these data being kept secret is normal; this is not security by obscurity.
a secure system uses the algorithms (which can be public in a system that is not relying on obscurity) and the secret data to transform plaintext into encryted text. encrypted text is "obscure" by definition, but this is not "security by obscurity" either.
unforgeable names are effectively encrypted text, in this broad view of things.
so unforgeable names need not imply that the system is relying on obscurity any more than, say, the fact that you cannot forge ssl certificates.
at least, that is how i would understand the term "unforgeable name". i am not speaking for any particular implementation.
|
|
Paul Snively - Re: Making reliable distributed systems in the presence of software errors
11/13/2003; 10:39:51 AM (reads: 966, responses: 0)
|
|
|
Manuel Simoni: I have a question: Isn't the concept of unforgeable names security by obscurity?
No.
The notion of "unforgeable names" has a very specific, very concrete meaning in the context of "capability security," which is where the term comes from. It refers to the impossibility, within a given execution context, of creating a valid "name" from bits that have leaked from the system. To make that somewhat more concrete, in C or C++, if a "name" is represented by a pointer and the bits that make up that pointer are leaked, an attacker who has the bits can reconstitute the pointer with a simple type cast. In some languages, Erlang apparently being one of them, it's not possible, given an arbitrary collection of bits, to reconstitute a "name" from them. That's what's meant by "unforgeable names" in the context of language-level capability security.
Having said that, once you go outside the language level, the distinction is less clear. For example, there are secure web app frameworks in which URLs contain suitably-encoded 128-bit cryptographically-strong pseudorandom numbers. This is indeed "security by obscurity," but when the odds of a randomly-selected number matching are one in some number that's larger than the number of atoms known to be in the universe, it's probably an OK tactic anyway. 
|
|
Patrick Logan - Re: Making reliable distributed systems in the presence of software errors
11/13/2003; 11:04:36 AM (reads: 967, responses: 0)
|
|
|
Don Box has an article on the future Indigo framework for Microsoft.
Reading the article you will notice a somewhat Erlang-like message passing influence. (More cumbersome, not nearly as featureful, but it is there. But that's kind of the state of web services in general right now.)
I know he acknowledged in a private conversation to being aware of and to some degree favorable of Erlang. I don't recall anything public. Maybe we can expect more of Erlang's system management and perhaps pattern-matching-driven programming built around Indigo and into some of the languages that support it.
Erlang's ease of development would be a great fit for what will be a nearly ubiquitous messaging infrastructure in a few years.
|
|
Luke Gorrie - Re: Making reliable distributed systems in the presence of software errors
11/13/2003; 1:15:11 PM (reads: 940, responses: 0)
|
|
|
Paul Snively: In some languages, Erlang apparently being one of them, it's not possible, given an arbitrary collection of bits, to reconstitute a "name" from them.
Actually, Erlang is not such a language, or at least isn't implemented this way. It provides ways to convert between process identifiers and (predictable) external representations. I think Joe's interest in capability-security type of things is a result of his moving to SICS and being exposed to dangerous influences ;-)
(I was surprised to read Peter Van Roy in CTM describe it as "disastrous" to lack capability-security in a programming language. I'd always thought this feature had pretty narrow practical applications to date, and was mostly interesting as a research topic. It would be interesting to read about some applications on LtU.)
|
|
Paul Snively - Re: Making reliable distributed systems in the presence of software errors
11/14/2003; 8:33:35 AM (reads: 812, responses: 0)
|
|
|
Luke Gorrie: Actually, Erlang is not such a language, or at least isn't implemented this way. It provides ways to convert between process identifiers and (predictable) external representations. I think Joe's interest in capability-security type of things is a result of his moving to SICS and being exposed to dangerous influences ;-)
Providing a way to convert between internal process identifiers and predictable external representations doesn't violate the notion of unforgeable names. The question really does revolve around the language's ability to shield you from forgery of something that cannot, even in principle, be prevented: leaking bits. A "predictable external representation" isn't leaked bits—by definition it's a cohesive, structured collection of bits—so if you're leaking predictable external representations then you have a security problem that's classical in nature and most certainly falls under the capability security purview.
As for Oz, I'm glad that they started off on the right (capability security) foot, but I wonder whether the issue raised at <http://www.mozart-oz.org/lists/oz-users/0861.html> has been resolved or not.
Luke: (I was surprised to read Peter Van Roy in CTM describe it as "disastrous" to lack capability-security in a programming language. I'd always thought this feature had pretty narrow practical applications to date, and was mostly interesting as a research topic. It would be interesting to read about some applications on LtU.)
I have the June 2003 PDF of CTM and cannot find the quote that you cite (the only use of "disastrous" that Acrobat Reader 6 finds is in reference to a lack of encapsulation, although it does appear in the "Secure Abstract Datatype" section). Could you perhaps point out where my search is going wrong? In any event, I agree with Peter's assessment: the moment a language purports to be useful in a multi-user distributed environment, a lack of at least capability-style discipline (an abstract store, lexical scoping, first-class functions), if not explicit support for capability security, is disastrous. And it's not an academic point, although industry has been slow to return to the lessons learned from, e.g. KeyKOS. To get the kind of leverage that we ultimately should expect from multiple parties collaborating via software through the Internet, we need to be able to engage in what Mark Miller evocatively refers to as "patterns of cooperation without vulnerability." That is, we need security that is both finer-grained and easier to use (!) than the standard perimeter/sandbox style of security that still seems to be believed to be the state of the art. The literature at <http://www.erights.org> is extensive and thorough. To see how all of this can apply in practice, download the current version of E and play with CapDesk. Better yet, get a friend or two or three to do likewise, and then use CapDesk in a distributed fashion. That might provide a concrete basis to some of the more abstract thinking about capabilities, which shows up in things like Smart Contracts and the Electronic Rights Transfer Protocol.
|
|
Luke Gorrie - Re: Making reliable distributed systems in the presence of software errors
11/14/2003; 1:09:45 PM (reads: 783, responses: 0)
|
|
|
Providing a way to convert between internal process identifiers and predictable external representations doesn't violate the notion of unforgeable names.
Your point is over my head, I'm afraid. What I mean is that there is no security within Erlang, as there is in Java or E. One of the many "nasty" things any Erlang code can do is guess the PID of every other process in the system and kill them. So an Erlang PID is not a 'capability', because anyone can (re)create them by guesswork.
To practically allow mutually suspicious/malicious programs to run safely in a shared Erlang node would require a lot more than making PIDs into capabilities. Unless I want to become a researcher and go the whole hog (as the E guys do), adding a "make_capability()" primitive or its scoping-rule equivalent isn't going to buy me anything, is it?
I have the June 2003 PDF of CTM and cannot find the quote that you cite (the only use of "disastrous" that Acrobat Reader 6 finds is in reference to a lack of encapsulation, although it does appear in the "Secure Abstract Datatype" section).
I meant the second bullet-point in that section, along with the examples that follow. They are talking about capability security. I wasn't aware of anyone except the E guys looking at capabilities in programming languages, so it piqued my interest. Are the mozart guys "doing an E" as well?
|
|
Peter Van Roy - Re: Making reliable distributed systems in the presence of software errors
11/16/2003; 12:31:21 PM (reads: 687, responses: 0)
|
|
|
I wasn't aware of anyone except the E guys looking at capabilities in programming languages, so it piqued my interest. Are the mozart guys "doing an E" as well?
We are looking at adding capability-based security to Oz and Mozart. While Oz is
a "safe" language (in the sense that language security is possible: adversaries
who stay within the language cannot break program invariants), there are lots of
little problems "around the edges". For example, what about implementation
security: protecting against adversaries who have access to the implementation?
What about providing the right primitives to help build realistic capability
programs (such as the E powerboxes)? What about the practical experience of
writing secure programs (such as the E Darpabrowser and Capdesk work)?
There are interesting questions regarding concurrency. E has a restricted concurrency
model: each 'vat' (secure collection of objects on a single OS process) has
a single thread and objects run by sharing this thread (through a single event
queue per vat). The reason for this restricted model has to do with security,
but I still don't understand why. Oz has a much richer concurrency model.
We think that this won't hurt security, because Oz has a rich sublanguage that
is concurrent and lazy and still declarative. Declarative implies deterministic,
and this is an important condition for security.
|
|
Darius Bacon - Re: Making reliable distributed systems in the presence of software errors
11/16/2003; 6:42:34 PM (reads: 668, responses: 0)
|
|
|
As I understand it, E's predecessor language, Joule, was a declarative concurrent language like Oz, and it was to support conventional imperative programming that they moved to the event-loop model. (I haven't used either Oz or Joule, myself.)
|
|
Peter Van Roy - Re: Making reliable distributed systems in the presence of software errors
11/17/2003; 3:35:51 AM (reads: 668, responses: 1)
|
|
|
... it was to support conventional imperative programming that they moved to the event-loop model.
I don't understand the connection. Conventional imperative programming can
be supported by richer concurrency models, e.g., Java has shared-state
concurrency with locks and monitors.
|
|
Isaac Gouy - Re: Making reliable distributed systems in the presence of software errors
11/17/2003; 1:32:31 PM (reads: 632, responses: 0)
|
|
With all the talk of Concurrency Oriented Programming, until reading through the thesis, I misunderstood quite a lot about what "ordinary" Erlang programming would be like.
"abstract out the concurrency" so the difficulties can be dealt with by expert programmers:
'all the code to do with concurrency, message passing etc is isolated in the "generic" part of the behaviour. The "problem specific" code only has pure sequential functions with well-defined types.' p158
and fail fast:
'The Erlang philosophy for handling errors
can be expressed in a number of slogans:
- Let some other process do the error recovery.
- If you can't do what you want to do, die.
- Let it crash.
- Do not program defensively.' p104
|
|
Mark S. Miller - Re: Making reliable distributed systems in the presence of software errors
11/17/2003; 5:42:21 PM (reads: 627, responses: 0)
|
|
Darius writes:
> As I understand it, E's predecessor language, Joule, was a
> declarative concurrent language like Oz, and it was to support
> conventional imperative programming that they moved to the event-
> loop model. (I haven't used either Oz or Joule, myself.)
Actually, Joule, Joule's ancestors in the Actors languages, and Joule's and Oz's common ancestors in the concurrent logic/constraint programming languages such as FCP and Janus (see http://www.erights.org/history/overview.html ) all use event-loop concurrency. What they don't have is support for conventional sequential-imperative programming. E is the first language in the Actors tradition to provide full support for sequential-imperative programming within the event-loop framework. Why did no previous Actors-tradition / event-loop-oriented programming language support conventional sequential-imperative programming?
Peter writes:
> I don't understand the connection. Conventional imperative
> programming can be supported by richer concurrency models, e.g.,
> Java has shared-state concurrency with locks and monitors.
For reasons stated at http://www.erights.org/elib/concurrency/event-loop.html the shared-memory multi-threading and locking paradigm has been an unmitigated disaster. (However, within this paradigm, Java is so much worse that we should avoid criticizing it, lest we be accused of picking on a straw man. Please understand that the points made here apply as well to Hoare's monitors and to Concurrent Pascal and Mesa.)
For thirty years, folks in the Actors tradition looked upon threads and locks with horror, and understandably but incorrectly concluded that that's the price you pay if you try to support both concurrency and conventional sequential imperative programming. Ken Kahn's essay at http://www.toontalk.com/english/concur.htm is representative of this mistake.
Most of the ideas in E are thirty years old -- Actors-style event loop concurrency, semi-transparent distributed object programming as communicating event loops, object references as capabilities, etc... The main innovation of E (by Doug Barnes) is simply to have gotten past the above impossibility assumption in order to actually try combining these styles of control flow, and finding they work together perfectly well. Of course, some more mechanism needed to be invented to reconcile these models, for which please see http://www.erights.org/elib/concurrency/index.html .
As to which is the "richer" model of concurrency, it depends on how you look at it. Obviously, we seek "more expressive" rather than "more complicated". For security, I understand how to pose such a question in order to escape the Turing Trap -- that all universal models can simulate each other, so they must all be equally "expressive". For concurrency, I don't know how to escape this trap. The three models we're discussing:
- Actors, concurrent logic/constraint programming, communicating event loops
- Shared memory multi-threading with locking
- E's support, within the Actor-style communicating event loop framework, for conventional sequential-imperative programming within an event loop
can all simulate each other, so how do we answer this question?
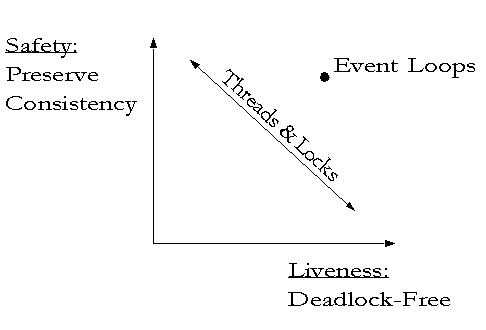
I suggest we examine the engineering tradeoff suggested by http://www.erights.org/elib/concurrency/images/badtradeoff.gif .
The only security issue I raise in this context is subsidiary to the Y axis on this diagram. If it's hard to preserve consistency -- if it's hard to write a program which doesn't have race condition bugs -- then programs with such bugs may be easily abused by an attacker. See the discussion of TOCTTOU errors in http://www.combex.com/papers/darpa-review/index.html .
For those who know E, the following may help:
If (like most people) you come to E from mostly sequential programming, it will seem like we took a conventional sequential-imperative programming language (E with "." but no "<-") and added "<-", promises, and eventual refs to it to get concurrency and distribution.
If you come to E from Actors, FCP, Janus, Joule, or Toontalk, it looks like we took a Joule-like Actors language (E with "<-" but no ".") and added "." and intra-vat near refs to it to support conventional sequential-imperative programming.
Historically, the truth is an odd mixture of these stories, but is closer to the second.
|
|
Darius Bacon - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 2:39:47 AM (reads: 573, responses: 0)
|
|
|
Sorry for the mistake -- I should have written "sequential event-loop model" or written up more details like Mark just provided. What I thought declarative Oz and Joule had in common was a model where dataflow is the main constraint on evaluation order. E "enriches" that with sequential execution during the response to a message; I'm not sure what Oz does. That's covered in the CTM book, right? Which looks really interesting, but too long for me right now. :/
It'd be nice to see a review article on the different ways programming languages do concurrency. I seem to recall Eiffel also has some kind of integration of dataflow with sequential programming, but I've completely forgotten the details.
|
|
andrew cooke - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 5:01:02 AM (reads: 566, responses: 2)
|
|
|
Finally got a chance to read some of this on the bus last night.
The COP (have I got that right?) analysis described might not be as simple as it first seems. How do you decide what influences what? This book describes how. Alternatively, maybe I'm just casting round for an application for the neat ideas in that book...
Someone else here said "do not program defensively". That's not quite true - Chapter 2 says that defensive programming is not necessary because language features do the appropriate checking/failure. So the defensiveness is required, it's just not explicit (and limited, at that level, to detecting the error and failing, rather than trying to correct).
I worked on one moderately distributed system a while ago and did part of the design of another recently. It's nice to see the ideas that we had been stumbling towards spelled out so clearly (and chastising to realise that we were reinventing - poorly - some very old stuff).
One thing I don't really follow is why Erlang is so closely related to Prolog. My naive idea of Prolog is that it's all about backtracking. So what's the advantage of doing Erlang in Prolog (initial prototype, later using something similar to the WAM) when Erlang doesn't have backtracking? Can someone enlighten me?
|
|
Ehud Lamm - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 5:12:56 AM (reads: 572, responses: 1)
|
|
|
I guess this paper is the primary source for answering this question.
|
|
andrew cooke - Re: Making reliable distributed systems in the presence of s
11/18/2003; 6:39:04 AM (reads: 577, responses: 0)
|
|
|
Thanks!
|
|
Isaac Gouy - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 7:56:44 AM (reads: 552, responses: 0)
|
|
"do not program defensively". That's not quite true
I've added the page number in section 4.3 where the quote comes from.
|
|
Peter Van Roy - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 10:53:56 AM (reads: 540, responses: 1)
|
|
The three models we're discussing:
- Actors, concurrent logic/constraint programming, communicating event loops
- Shared memory multi-threading with locking
- E's support, within the Actor-style communicating event loop framework, for conventional sequential-imperative programming within an event loop
can all simulate each other, so how do we answer this question?
You forgot the model I mentioned: declarative concurrency. This model
is not equivalent to the three models you mention, since it cannot express
observable nondeterminism (a.k.a. race conditions). This model is
both declarative (functional) and concurrent. Laziness can be added to it.
(This is all explained in chapter 4 of my book.)
So, what about security in the declarative concurrent model?
|
|
Peter Van Roy - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 10:57:48 AM (reads: 530, responses: 0)
|
|
|
Just to make things clear: I obviously do not pretend that you can do all concurrent
programming in the declarative concurrent model! But I do think that it should be
used whenever possible, and that nondeterminism should be isolated in small
parts of the program.
|
|
Peter Van Roy - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 11:19:30 AM (reads: 528, responses: 1)
|
|
|
Obviously, we seek "more expressive" rather than "more complicated". For security, I understand how to pose such a question in order to escape the Turing Trap -- that all universal models can simulate each other, so they must all be equally "expressive". For concurrency, I don't know how to escape this trap.
Say you have two computation models, A and B, and the
difference is that B has one more concept than A. Then B is more expressive than
A if a B program that uses the concept can only be encoded in A with nonlocal
changes to the program. A few examples of concepts that increase the expressiveness of a simple functional language are: exceptions (encoding
requires boolean parameters added along the whole call path), explicit state
(encoding requires adding threaded parameters throughout the program),
concurrency (encoding requires adding a scheduler and chopping the program
in pieces that correspond to time slices). All the computation models of CTM
are organized according to this principle; see appendix D for more information.
There are three practical concurrent programming models considered in CTM
(lots of variations are possible, but these three are the basic ones):
declarative concurrency, message-passing concurrency (= declarative concurrency
plus explicit communication channel), shared-state concurrency (= declarative
concurrency plus explicit state). The last one is the most complicated to
program in, so it is very surprising that it is the most popular and
most often taught to students!
|
|
Chris Rathman - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 11:37:14 AM (reads: 525, responses: 0)
|
|
Would it be fair to categorize the sequencing on these as:
- simultaneous: declarative
- asynchronous: message-passing
- synchronous: shared-state
?
|
|
Mark S. Miller - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 11:51:52 AM (reads: 540, responses: 0)
|
|
Peter writes:
> You forgot the model I mentioned: declarative concurrency. This
> model is not equivalent to the three models you mention, since it
> cannot express observable nondeterminism (a.k.a. race conditions).
> This model is both declarative (functional) and concurrent.
> Laziness can be added to it. (This is all explained in chapter 4
> of my book.)
>
> So, what about security in the declarative concurrent model?
I didn't mention declarative concurrency because I don't yet understand it. In any case, I have never argued that declarative concurrency has security problems -- I don't yet understand it well enough to have an informed opinion. Rather, I was responding to your use of Java as a positive example of, presumably, shared memory multi threading. For the reasons indicated, I think this paradigm is a mistake, and that Java's embodiment of this paradigm is a rather horribly worse mistake. See
I look forward to understanding declarative concurrency and its implications for security.
Btw, for completeness, I mention another paradigm: in Barbara Liskov's Argus language, computation proceeds by nested isolated atomic transactions. These are isolated not by locking, but by spawning hypothetical versions, and later analyzing read-write sets to decide which transactions may be committed without conflict (i.e., would be "serializable"). The original (non-Flat) Concurrent Prolog proposal, with its deep guards, can be seen as being partially within this paradigm. It has many of both the safety and liveness advantages of event-loops, and it has somewhat greater expressiveness. I am unaware of practical implementations of either Argus or deep-guard Concurrent Prolog, which may be why we don't hear much about this paradigm in programming language circles.
|
|
Mark S. Miller - Re: Making reliable distributed systems in the presence of software errors
11/18/2003; 5:39:19 PM (reads: 517, responses: 0)
|
|
Peter writes:
> Then B is more expressive than A if a B program that uses the
> concept can only be encoded in A with nonlocal changes to the
> program.
I think this definition of "more expressive" is wonderful, and includes my similar thoughts on security as a special case. Cool!
You then mention the three concurrency models considered in CTM. Using you definition, which is more expressive than which? Is either "message-passing concurrency" or "shared-state concurrency" more expressive than the other? (If this is already covered in your book, feel free to just point at the answer.)
Btw, given your definition of "more expressive", it's important to point out that an individual case of "more expressive" may be worse or better depending on the specifics, and on other goals.
Note that your definition cannot say, of Actors and Java, whether one is more expressive than the other. They start with almost disjoint sets of concepts, so the question you pose cannot be applied.
|
|
Peter Van Roy - Re: Making reliable distributed systems in the presence of software errors
11/19/2003; 12:21:53 AM (reads: 500, responses: 0)
|
|
|
You then mention the three concurrency models considered in CTM. Using your definition, which is more expressive than which? Is either "message-passing concurrency" or "shared-state concurrency" more expressive than the other? (If this is already covered in your book, feel free to just point at the answer.)
According to the CTM definition, message-passing and shared-state concurrency are equivalent in expressiveness (and both are more expressive than declarative concurrency). The communication channel of message-passing concurrency can be implemented directly
with explicit state and vice versa. So no nonlocal changes are needed.
(BTW, this is a classic result: there is a famous paper of Lauer and Needham,
"On the Duality of Operating System Structures", published in 1978, that
introduces this equivalence.)
But programming is very different in message-passing style versus shared-state style.
This shows that you need more than expressiveness to compare languages.
The precise set of concepts matters too.
Note that your definition cannot say, of Actors and Java, whether one is more expressive than the other. They start with almost disjoint sets of concepts, so the question you pose cannot be applied.
You have to look carefully at the concepts. Actors and Java are probably not as disjoint as they might appear at first glance (compare, e.g., chapter 5 and chapter 8
of CTM). But, in general you are right. Expressiveness is a partial order. You have
to give the lattice structure and place the languages in it.
simultaneous: declarative
I wouldn't put it this way. Declarative concurrency takes a standard sequential functional program,
which executes in "batch" style, and lets it execute in "incremental" style.
I think you'll just have to go read chapter 4 of CTM. Don't worry: the basic
idea is given in the first two pages (with example code)!
|
|
Dave Herman - Re: Making reliable distributed systems in the presence of software errors
11/19/2003; 2:59:38 AM (reads: 491, responses: 0)
|
|
>> Then B is more expressive than A if a B program that uses the
>> concept can only be encoded in A with nonlocal changes to the
>> program.
>
> I think this definition of "more expressive" is wonderful, and includes
> my similar thoughts on security as a special case. Cool!
Just to give credit where it's due: On the Expressive Power of Programming Languages
|
|
Peter Van Roy - Re: Making reliable distributed systems in the presence of software errors
11/19/2003; 6:02:09 AM (reads: 480, responses: 0)
|
|
|
Just to give credit where it's due: On the Expressive Power of Programming Languages
Yes, this article gives the same definition of expressiveness and develops it
in a more formal way than I do in CTM.
For the record, I came up with this definition independently and used it to
structure the whole of CTM, covering many more concepts than this article
covers. I learned of the article on Lambda the Ultimate recently, much
too late to influence the content of CTM.
|
|
|
|
{kind=link}